
- Carga de datos
- Filtrado de datos
- Representación gráfica
- Regresión lineal
- Análisis de diferencias entre grupos mediante t-student
Unos investigadores desarrollan un nuevo entorno
virtual de aprendizaje basado en Google Apps. Para evaluar la incidencia de
la utilización de este nuevo entorno en las calificaciones de los
estudiantes, durante dos años se realiza un estudio de caso con dos grupos de
estudiantes: un grupo de control que utiliza Moodle y un grupo experimental
que utiliza Google Apps.
|
SE PIDE: para cada uno de los años, analizar si existen diferencias estadísticamente significativas entre las calificaciones de ambos grupos.
Para los dos años, vamos a realizar las siguientes operaciones:
- Carga de datos
- Filtrado de datos
- Representación gráfica
- Regresión lineal
- Análisis de diferencias entre grupos mediante t-student
- Año 1:
Descargamos el fichero de datos con el que vamos a trabajar. El fichero es un archivo CSV con una estructura tabulada. Tal y como se puede observar, en el fichero constan los datos de 40 estudiantes de los cuales 20 utilizaron un entorno Moodle y 20 utilizaron un entorno Google Apps durante el Año 1. Entre esos datos figuran el grupo o entorno y la calificación final de cada estudiante.
 |
| Archivo Notas-2grupos-v1.csv |
Abrimos la interfaz RStudio y cargamos el fichero de datos.

A continuación, debemos indicar que nuestro contenido del fichero incluya una cabecera, utilizado entre las variables. Este es el resultado:
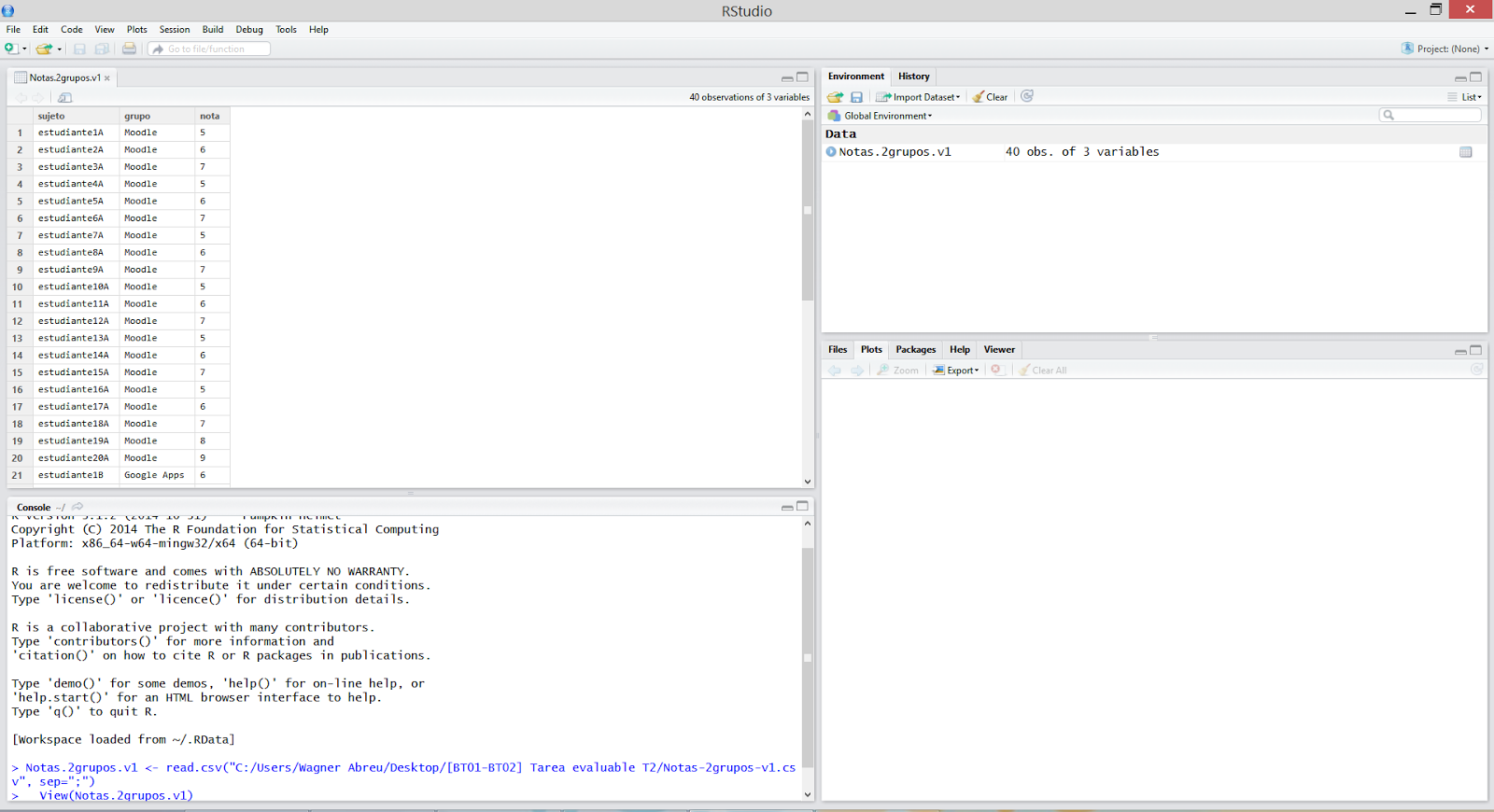
2. Filtrado de datos.
Para filtrar los sujetos por tipo grupo, escribimos los siguientes comandos en la consola de R:
> datosMoodle <-subset(Notas.2grupos.v1, grupo=="Moodle")
> datosGoogleApps <-subset(Notas.2grupos.v1, grupo=="Google Apps")
Al ejecutar estos dos comandos, se crearan dos variables: datosMoodle y datosGoogleApps.


3. Representación gráfica.
Vamos a crear el "marco" sobre el que representar los puntos (los estudiantes). Es necesario definir unos ejes X, Y que abarque el rango de valores de las variables que se desea representar (nota). Para ello, introducimos el siguiente comando:
> plot(Notas.2grupos.v1$nota, ylab="nota", xlab="grupo", type="n")

> points(datosMoodle$nota ~ datosMoodle$nota, col="blue", cex=0.9)
> points(datosGoogleApps$nota ~ datosGoogleApps$nota, col="red", cex=0.9)

Análisis: A partir de la observación de las distribuciones de puntos de cada grupo, podemos inferir que conforme aumenta el tamaño de la red personal de los estudiantes, también lo hace la calificación final obtenida por éstos. Para confirmar este hecho, procedemos a ajustar cada una de las distribuciones de puntos a una recta mediante una regresión lineal simple.
4. Regresión lineal.
El comando lm calcula los parámetros del modelo:
> lmMoodle <- lm(datosMoodle$nota ~ datosMoodle$nota)
> lmGoogleApps <- lm(datosGoogleApps$nota ~ datosGoogleApps$nota)
> abline(lmMoodle, col="blue", lwd=2) > abline(lmGoogleApps, col="red", lwd=2)


5. Análisis de diferencias entre grupos mediante t-student.
En la figura anterior, podemos observar que la nube de puntos correspondiente al grupo de estudiantes que utilizó el entorno Google Apps tiene una calificación final mayor y calificaciones mejores que el grupo de estudiantes que utilizaron el entorno Moodle. Calculamos la media para hacernos una idea de la medida en que dichos indicadores varían.
Media de la calificación final en cada grupo:
> with(Notas.2grupos.v1, tapply(nota, list(grupo), mean)) Google Apps Moodle 7.25 6.25
Por lo tanto, un estudiante que utilizó el entorno Google Apps obtuvo, de media, 1 pto. más (sobre 100) que un estudiante que utilizó el entorno Moodle. No parece una diferencia significativa.
Finalmente, queremos saber si las diferencias observadas entre grupos en la calificación final son ESTADISTICAMENTE significativas.
Ejecutamos el comando para realizar el test de t de student.
> t.test(datosMoodle$nota, datosGoogleApps$nota)
Y obtenemos los resultados del análisis:

En este caso, p-value = 0.007427 = 0.7427% por lo que el riesgo a equivocarnos es pequeño.
Por tanto, en lo que respecta a la calificación final concluimos que:
- en este estudio concreto no percibimos una diferencia significativa entre los valores de las medias de cada grupo.
- la diferencia entre las calificaciones de los estudiantes de uno y otro grupo es estadísticamente significativa.
- Año 2:
1. Carga de datos.


2. Filtrado de datos.
Antes de filtrar los sujetos por grupos, vemos que en este fichero, el delimitador o separador (#) que contiene las columnas, no es leido por RStudio.
Modificamos el separador por "# "en la consola de R y ejecutamos:
Ahora podemos filtrar los grupos:

Calculamos la media para hacernos una idea de la medida en que dichos indicadores varían de un grupo a otro.
Media de la calificación final en cada grupo:
Para estar seguros de nuestro estudio, hacemos una prueba de t-student para ver el grado de confianza.

En este último caso, p-value = 0.08832 = 8.832% por lo que el riesgo a equivocarnos es grande.
Por tanto, en lo que respecta a la calificación final concluimos que:
Descargamos el fichero de datos con el que vamos a trabajar. El fichero es un archivo CSV con una estructura tabulada. Tal y como se puede observar, en el fichero constan los datos de 40 estudiantes de los cuales 20 utilizaron un entorno Moodle y 20 utilizaron un entorno Google Apps durante el Año 2. Entre los datos figuran el grupo o entorno y la calificación final de cada estudiante.

Abrimos la interfaz RStudio y cargamos el fichero de datos.


2. Filtrado de datos.
Antes de filtrar los sujetos por grupos, vemos que en este fichero, el delimitador o separador (#) que contiene las columnas, no es leido por RStudio.
Modificamos el separador por "# "en la consola de R y ejecutamos:
> Notas.2grupos.v2 <- read.csv("C:/Users/Wagner Abreu/Desktop/[BT01-BT02] Tarea evaluable T2/Notas-2grupos-v2.csv", sep="#")



Calculamos la media para hacernos una idea de la medida en que dichos indicadores varían de un grupo a otro.
Media de la calificación final en cada grupo:
> with(Notas.2grupos.v2, tapply(nota, list(grupo), mean)) Google Apps Moodle 7.25 6.55
Podemos observar en este caso, que un estudiante que utilizó Google Apps obtuvo, de media, 0.71 pto. más que un estudiante que utilizó el entorno Moodle.
Para estar seguros de nuestro estudio, hacemos una prueba de t-student para ver el grado de confianza.

En este último caso, p-value = 0.08832 = 8.832% por lo que el riesgo a equivocarnos es grande.
Por tanto, en lo que respecta a la calificación final concluimos que:
- en este estudio concreto percibimos una diferencia significativa entre los valores de las medias de cada grupo.
- la diferencia entre las calificaciones de los estudiantes de uno y otro grupo no es estadísticamente significativa.
Análisis final

{kind=link}
{kind=link}
{kind=link}